Добрый день. Хочу поделиться опытом установки скансервера на базе Ubuntu Server
Сервер сканирования позволяет сканировать с любого компьютера в сети без установки специального ПО. Все функции сканирования возлагаются на один компьютер с серверным ПО на базе Linux. Установка драйверов на компьютеры пользователей не требуется. С переходом от одной версии windows к другой для пользователей ничего не меняется.
За основу был взят проект PHiLLIP KliEWER
он был раньше здесь
http://scannerserver.online02.comНо сейчас проект прекратил свое развитие и сайта нет.
Код проекта сильно изменен, ибо оригинал был сильно заброшен где-то посередине.
Архив оригинала найдете по ссылке
http://yarvobler.narod.ru/scanserver/original/scan_1.1.9.tarОтличия от оригинала
1) Самое главное предоставляется выбор сканировать c автоподачи стопку бумаги или один лист со стекла. При этом со стекла сканируется в формат JPG. С автоподачи в многостраничный PDF.
2) Любое изображение JPG со стекла нажатием одной кнопки переводится в PDF
3) Ссылка на страницу конфигурации- там где меняется цветовая тема и редактируется конфигурация сканеров скрыта от пользователей. Чтоб в корпоративной среде любопытный пользователь случайно не нарушил работоспособность системы.
4) Все форматы кроме jpg и pdf не используются при сканировании.
Рассмотрим установку такового на Ubuntu 14.04 Server.
Нам понадобятся web server apache2, утилиты сканирования sane, утилиты для обработки изображений netpbm и imagemagick.
Кроме того, если мы работаем с техникой HP, потребуется набор утилит и драйверов Hewlett-Packard - hplip, samba — сервер для доступа к истории сканирования через проводник windows, ssh сервер для удаленного управления.
samba и ssh ставится еще при установке сервера, остальное устанавливается командой
sudo apt-get install sane-utils netpbm apache2 imagemagick
sudo apt-get install php libapache2-mod-php
Установщик hplip можно скачать (самую последнюю версию) с официального сайта
http://hplipopensource.com/hplip-web/gethplip.htmlили
sudo apt-get install hplip
(Тиражируя проект на платформе ubuntu 16.04 понял что ставить hplip лучше вторым способом, ибо крайний hplip конфликтует с версией python- но это косяки компании HP )
Установив все пакеты и утилиты приступим к настройке сканеров.
Устройства Hewlett-Packard ставятся командой
sudo hp-setup -i ip_адрес_сканера
в процессе установки вам будет задано несколько вопросов, на которые можно отвечать нажатием ENTER, тогда будут приняты ответы по умолчанию (помеченные знаком *).
На процесс сканирования эти параметры все равно не повлияют.
проверить наличие устройства сканирования
sudo scanimage -L
Переходим к настройке и установке сервера.
в конфигурационный файл apache, который находится здесь
/etc/apache2/apache2.conf
добавить строку (разрешить исполнение скриптов)
AddHandler cgi-script .cgi
выполним команду (подключение модуля исполнения cgi для apache2)
sudo a2enmod cgi
Теперь настройка сайта
/etc/apache2/sites-enabled/000-default
пример настройки находится здесь
http://yarvobler.narod.ru/scanserver/000-default.confглавное разрешить исполнение cgi
<Directory /var/www/>
Options Indexes FollowSymLinks MultiViews ExecCGI
AllowOverride All
Order allow,deny
allow from all
</Directory>
Перезагрузим apache2
sudo service apache2 restart
Сам код сервера разворачивается в /var/www
он берется отсюда
http://yarvobler.narod.ru/scanserver/scanserver.tgzcd /var/www
sudo wget
http://yarvobler.narod.ru/scanserver/scanserver.tgzsudo tar xvfz scanserver.tgz
После этого запускается сервер сканирования
http://server_ip_addressПользователь для получения сканированного изображения должен
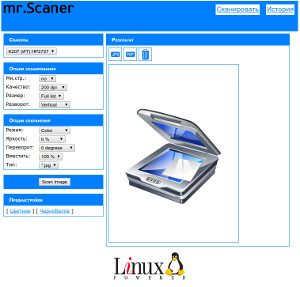
1) Выбрать сканер из выпадающего списка сканеров.
2) Выбрать источник сканирования: планшет с одним листом или автоподатчик с пачкой листов.
3) определить качество сканирования или пропустив этот этап сразу нажать кнопку Scan Image.
4) Полученные результаты сохранить на свой компьютер. Одностраничный документ в pdf или jpg. Многостраничный с автоподатчика в pdf (один лист с автоподатчика все равно будет считаться многостраничным документом)
Конфигурация сервера расположена в каталоге /var/www/config
Сама страница конфигурации закрыта от случайного доступа пользователю, но мы можем ее вызвать по секретной ссылке
http://server_ip_address/index.cgi?page=configВсе доступные серверу сканеры для доступности пользователю должны быть прописаны в конфигурационный файл
/var/www/config/scanners.conf
Он представляет собой набор строк вида
ID=номер по порядку INUSE=0 DEVICE=Системное_имя NAME=Произвольное имя понятное пользователя
Например
ID=01 INUSE=0 DEVICE=hpaio:/net/HP_LaserJet_M2727nf_MFP?ip=10.5.7.20 NAME=K207 (ИТ) HP2727
Если сканеров больше 9 то начинать нумерацию ID 01,02… 99 обязательно c нуля первые 9. Для 9 сканеров и меньше можно обойтись без нулей в номере ID.
Системное имя можно узнать командой
scanimage -L
Система установлена и работает с более десятка сканеров в корпоративной среде одного из предприятий. На предприятии используется только сканирующие устройства производителя Hewlett-Packard. С устройствами других производителей система не тестировалась. Но это не значит ваш сканер не будет работать, судя по архивам форума умершего сайта проекта, люди цепляли разные сканеры Canon, Mustec, Epson и не только по ip, но и по USB. Если он доступен через sane utils, то теоретически все будет работать.
P.S. В ходе эксплуатации системы возникла потребность ограничить доступ к сканированным документам специфических отделов предприятия.
Один из вариантов решения проблемы.
Если документы забираются сотрудниками предприятия только по web через браузер, то в раздел на сервере /var/www/
надо поместить файл с именем .htaccess и со следующим содержанием
#allow to view scans from scanner with id=
01 only client with ip=
10.5.9.115<Files ~ "(
01.jpg)$">
Order Deny,Allow
Deny from all
Allow from
10.5.9.115</Files>
<Files ~ "(
01.jpg.pdf)$">
Order Deny,Allow
Deny from all
Allow from
10.5.9.115</Files>
Вам надо только прописать вместо
01 соответствующий ID из /var/www/config/scanners.conf и
ip адрес или адреса клиентов, которые будут видеть документ с данного сканера. Остальные не смогут увидеть даже миниатюры в истории.
Разумеется в файле конфигурации сайта /etc/apache2/sites-enabled/000-default надо разрешить исполнение .htaccess
Все строки типа AllowOverride None заменить на AllowOverride All.
Тогда доступ к папке где хранятся сканы по samba не рассматривается или решается по вашему усмотрению.
PS. В 2020 году возникла потребность вернуться к теме и установить сервер сканирования на ubuntu 20.04
Как и ожидал сразу ничего не завелось но по порядку
1) отличия в установке hplip
sudo apt install hplip - дает просто набор команд без поддержки устройств - в топку
устанавливал скачивая с сайта hp
wget
https://nchc.dl.sourceforge.net/project/hplip/hplip/3.20.5/hplip-3.20.5.run chmod -R 755 hplip-3.20.5.run
не торопитесь запускать, в системе должен стоять и быть активным cups иначе вас ждет ругань про неудовлетворенные зависимости. Да если cups стоит но незапущен- сообщение тоже установите зависимости вручную.
sudo apt install cups
sudo systemctl start cups
sudo systemctl enable cups
а вот теперь можно ставить hplip
./hplip-3.20.5.run
остальные зависимости пакетов он доставит сам.
2) Нифига не сканирует код перенесенный с прежнего сервера
поставил код сохранения выполняемых команд в debug.txt
вот как изменился рабочий файл index.cgi в ubuntu 20.04
wget
http://yarvobler.narod.ru/scanserver/index.cgi.tar.gzпоставлены метки сохраняющие вывод команд в debug.txt
их можно закоментить все, что заканчиваются на >> debug.txt # info for debug
Выяснил что sane utils изменили формат и строка
scanimage -d $DEVICE --resolution $QUALITY $SIZE -l 0 -t 0 -x 215 -y 296 --mode $MODE $BATCH --format=ppm > /tmp/scan_file$SCANNER.ppm
ругается на формат ppm (не поддерживается)- сменил на pnm
начало сканировать.
3) Формат PDF перестал предоставляться при сканировании с авто-податчика и конвертации из jpg
опять помог debug.txt
вставил сохраненную в нем команду в строку терминала, ответ
convert-im6.q16: attempt to perform an operation not allowed by the security policy `PDF' @ error/constitute.c/IsCoderAuthorized/408.
Забил строку в поиск оказалось надо разрешить теперь imagemagic конвертировать PDF
nano /etc/ImageMagick-6/policy.xml
в конце должно быть
<policy domain="coder" rights="read | write" pattern="PDF" />
</policymap>
Ура ! все снова работает, на новой платформе ubuntu 20.04

 Тема: Сервер сканирования на ubuntu server с web интерфейсом (Прочитано 15997 раз)
Тема: Сервер сканирования на ubuntu server с web интерфейсом (Прочитано 15997 раз)